Ispravljač (neuronske mreže)
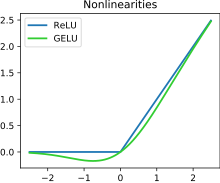
U kontekstu veštačkih neuronskih mreža, funkcija aktivacije ispravljača ili ReLU (Rectified Linear Unit) [1] [2] je aktivaciona funkcija definisana kao pozitivan deo svog argumenta:

gde x predstavlja ulaz u neuron. Ovo je inače poznato i kao funkcija rampe i analogno je polutalasnom ispravljanju koja je oblast u elektrotehnici .
Ova aktivaciona funkcija se počela pojavljivati u kontekstu ekstrakcije vizuelnih karakteristika u hijerarhijskim neuronskim mrežama počevši od kraja 1960-ih godina. [3] [4] Kasnije se tvrdilo da ima jake biološke motive i matematička opravdanja. [5] 2011. godine je otkriveno da omogućava bolju obuku dubljih mreža, [6] u poređenju sa široko korišćenim aktivacionim funkcijama od pre 2011. godine, na primer, logistički sigmoid (koji je inspirisan teorijom verovatnoće ; pogledajte i logističku regresiju ) i njegov praktičniji [7] ekvivalent, hiperbolička tangenta . Ispravljač je, od 2017. godine, najpopularnija aktivaciona funkcija za duboke neuronske mreže . [8]
Ispravljene linearne jedinice uglavnom nalaze primenu u kompjuterskom vidu [9] i prepoznavanju govora [10] [11] tako što koriste duboke neuronske mreže i računarsku neuronauku . [12] [13] [14]
Prednosti
uredi- Retka aktivacija: Na primer, u nasumično inicijalizovanoj mreži, samo oko 50% skrivenih jedinica je aktivirano (imaju ne-nultnu izlaznu vrednost).
- Bolje širenje gradijenta: Manje problema sa nestajajućim gradijentom u poređenju sa funkcijama sigmoidalne aktivacije koje se zasićuju u oba smera. [9]
- Efikasno računanje: Samo poređenje, sabiranje i množenje.
- Invarijantna razmera: .

Aktivacione funkcije za ispravljanje su korišćene za razdvajanje specifične ekscitacije i nespecifičnih inhibicija u neuralno apstraktnoj piramidi, koja je obučena na nadgledajući način da nauči nekoliko zadataka kompjuterske vizije. [15] U 2011. godini, [9] pokazalo se da upotreba ispravljača kao nelinearnosti omogućava obuku duboko nadgledanih neuronskih mreža bez potrebe za prethodnom obukom bez nadzora . Ispravljene linearne jedinice, u poređenju sa sigmoidnom funkcijom ili sličnim aktivacionim funkcijama, omogućavaju brži i efikasniji trening dubokih neuronskih arhitektura na velikim i složenim skupovima podataka.
Potencijalni problemi
uredi- Nije diferencijabilan na nuli; međutim, može se razlikovati bilo gde drugde, a vrednost derivata na nuli može se proizvoljno izabrati da bude 0 ili 1.
- Nije nultno-centriran.
- Neograničenost
- Problem umiranja ReLU-a: ReLU (Rectified Linear Unit) neuroni ponekad mogu biti gurnuti u stanja u kojima postaju neaktivni za suštinski sve ulaze. U ovom stanju, nijedan od gradijenata ne teče unazad kroz neuron, tako da se neuron zaglavi u trajno neaktivnom stanju i „umire“. Ovo je oblik problema nestajanja gradijenta . U nekim slučajevima, veliki broj neurona u mreži može da se zaglavi u mrtvim stanjima, efektivno smanjujući kapacitet modela. Ovaj problem se obično javlja kada je stopa učenja postavljena previsoko. Može se ublažiti korišćenjem propuštajućih ReLU-ova, koji dodeljuju mali pozitivan nagib za h < 0; međutim, performanse su smanjene.
Varijante
urediKomadično-linearne varijante
urediPropuštajući ReLU
urediPropuštajući ReLU-ovi dozvoljavaju mali, pozitivan gradijent kada jedinica nije aktivna. Sledeća funkcija glasi: [11]

Parametrizovan ReLU
urediParametrizovani ReLU-ovi (PReLUs) razvijaju ovu ideju dalje tako što pretvaraju koeficijent curenja u parametar koji se uči zajedno sa drugim parametrima neuronske mreže. [16]

Imajte na umu da su za a ≤ 1 ove dve funkcije ekvivalentne maksimalnoj vrednosti funkcije koja se nalazi ispod

i samim tim imaju vezu sa "maxout" mrežama. [17]
Druge nelinearne varijante
urediGausova linearna jedinica greške (GELU)
urediGELU predstavlja glatku aproksimaciju ispravljača. Ima nemonotonski „bump“ kada je h < 0, i služi kao podrazumevana aktivacija za modele kao što je BERT . [18]
,

gde Φ( h ) predstavlja kumulativna funkcija raspodele standardne normalne raspodele .
Ova aktivaciona funkcija je ilustrovana na slici koja se nalazi na početku ovog članka.
SiLU
urediSiLU (Sigmoidova Linearna Jedinica) ili funkcija swish [19] je još jedna glatka aproksimacija koja je prvi put skovana u GELU radu. [20]

gde je sigmoidna funkcija .

Softplus
urediAproksimacija ispravljača glatkog i laganog oblika predstavlja navedenu analitičku funkciju koja je predstavljena funkcijom ispod:

i ta funkcija se naziva softplus [21] [9] ili SmoothReLU . [22] Za velike negativne vrednosti je otprilike jednako dakle nešto iznad 0, dok za velike pozitivne vrednosti je otprilike jednako tek malo iznad .



Parametar oštrine može biti uključeno:


Izvod softplus-a jednak je logističkoj funkciji . Počevši od parametarske verzije,

Logistička sigmoidna funkcija je približna aproksimacija izvoda ispravljača, odnosno Hevisajdove korak funkcije .
Multivarijabilna generalizacija softplus-a sa jednom promenljivom je [1]LogSumExp sa prvim argumentom koji je postavljen na nulu:

Funkcija LogSumExp je

a njegov gradijent predstavlja [2]softmax ; softmax sa prvim argumentom koji je postavljen na nulu je multivarijabilna generalizacija logističke funkcije. I LogSumExp i softmax se koriste u mašinskom učenju.
ELU
urediEksponencijalne linearne jedinice pokušavaju da učine srednje aktivacije budu bliže nuli, što ubrzava proces učenja. Pokazalo se da ELU mogu postići veću tačnost klasifikacije od ReLU-ova. [23]

gde je hiperparametar koji treba podesiti, i je ograničenje.


ELU se može posmatrati kao da je izglađena verzija pomerenog ReLU (SReLU), koji ima oblik funkcije s obzirom na isto tumačenje .

Mish
urediMish funkcija se takođe može ikoristiti kao aproksimacija ispravljača glatkog oblika. [24] Definiše se kao

gde predstavlja hiperboličnu tangentu i je [3]softplus funkcija.


Miš je nemonoton i samostalan . [25] Inspirisan je [4]Swish -om, koji je varijanta ReLU-a . [25]
Vidi još
uredi- ^ Brownlee, Jason (8. 1. 2019). „A Gentle Introduction to the Rectified Linear Unit (ReLU)”. Machine Learning Mastery. Pristupljeno 8. 4. 2021.
- ^ Liu, Danqing (30. 11. 2017). „A Practical Guide to ReLU”. Medium (na jeziku: engleski). Pristupljeno 8. 4. 2021.
- ^ Fukushima, K. (1969). „Visual feature extraction by a multilayered network of analog threshold elements”. IEEE Transactions on Systems Science and Cybernetics. 5 (4): 322—333. doi:10.1109/TSSC.1969.300225.
- ^ Fukushima, K.; Miyake, S. (1982). „Neocognitron: A self-organizing neural network model for a mechanism of visual pattern recognition.”. In Competition and Cooperation in Neural Nets. Lecture Notes in Biomathematics. Springer. 45: 267—285. ISBN 978-3-540-11574-8. doi:10.1007/978-3-642-46466-9_18.
- ^ Hahnloser, R.; Sarpeshkar, R.; Mahowald, M. A.; Douglas, R. J.; Seung, H. S. (2000). „Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit”. Nature. 405 (6789): 947—951. Bibcode:2000Natur.405..947H. PMID 10879535. doi:10.1038/35016072.
- ^ . Arhivirano iz originala
|archive-url=zahteva|url=(pomoć)|archive-url=zahteva|archive-date=(pomoć). g. Nedostaje ili je prazan parametar|title=(pomoć) - ^ „Efficient BackProp” (PDF). Neural Networks: Tricks of the Trade. Springer. 1998.
- ^ Ramachandran, Prajit; Barret, Zoph (16. 10. 2017). „Searching for Activation Functions”. arXiv:1710.05941
 [cs.NE].
[cs.NE].
- ^ a b v g . Arhivirano iz originala
|archive-url=zahteva|url=(pomoć)|archive-url=zahteva|archive-date=(pomoć). g. Nedostaje ili je prazan parametar|title=(pomoć)Xavier Glorot, Antoine Bordes and Yoshua Bengio (2011). Deep sparse rectifier neural networks Arhivirano na sajtu Wayback Machine (13. decembar 2016) (PDF). AISTATS.Rectifier and softplus activation functions. The second one is a smooth version of the first.
{{cite conference}}: CS1 maint: uses authors parameter (link) - ^ . Arhivirano iz originala
|archive-url=zahteva|url=(pomoć)|archive-url=zahteva|archive-date=(pomoć). g. Nedostaje ili je prazan parametar|title=(pomoć) - ^ a b Andrew L. Maas, Awni Y. Hannun, Andrew Y. Ng (2014). Rectifier Nonlinearities Improve Neural Network Acoustic Models.
- ^ Hansel, D.; van Vreeswijk, C. (2002). „How noise contributes to contrast invariance of orientation tuning in cat visual cortex”. J. Neurosci. 22 (12): 5118—5128. PMC 6757721 . PMID 12077207. doi:10.1523/JNEUROSCI.22-12-05118.2002.
- ^ Kadmon, Jonathan; Sompolinsky, Haim (2015-11-19). „Transition to Chaos in Random Neuronal Networks”. Physical Review X. 5 (4): 041030. Bibcode:2015PhRvX...5d1030K. arXiv:1508.06486 . doi:10.1103/PhysRevX.5.041030.
- ^ Engelken, Rainer; Wolf, Fred (2020-06-03). „Lyapunov spectra of chaotic recurrent neural networks”. arXiv:2006.02427 [nlin.CD].
- ^ Behnke, Sven (2003). Hierarchical Neural Networks for Image Interpretation. Lecture Notes in Computer Science. 2766. Springer. ISBN 978-3-540-40722-5. doi:10.1007/b11963.
- ^ He, Kaiming; Zhang, Xiangyu. „Delving Deep into Rectifiers: Surpassing Human-Level Performance on Image Net Classification”. arXiv:1502.01852 [cs.CV].
- ^ He, Kaiming; Zhang, Xiangyu. „Delving Deep into Rectifiers: Surpassing Human-Level Performance on Image Net Classification”. arXiv:1502.01852 [cs.CV].He, Kaiming; Zhang, Xiangyu; Ren, Shaoqing; Sun, Jian (2015). "Delving Deep into Rectifiers: Surpassing Human-Level Performance on Image Net Classification". arXiv:1502.01852 [cs.CV].
- ^ Hendrycks, Dan; Gimpel, Kevin. „Gaussian Error Linear Units (GELUs)”. arXiv:1606.08415 [cs.LG].
- ^ Diganta Misra (23. 8. 2019), Mish: A Self Regularized Non-Monotonic Activation Function (PDF), arXiv:1908.08681v1 , Pristupljeno 26. 3. 2022
- ^ Hendrycks, Dan; Gimpel, Kevin. „Gaussian Error Linear Units (GELUs)”. arXiv:1606.08415 [cs.LG].Hendrycks, Dan; Gimpel, Kevin (2016). "Gaussian Error Linear Units (GELUs)". arXiv:1606.08415 [cs.LG].
- ^ Dugas, Charles; Bengio, Yoshua; Bélisle, François; Nadeau, Claude; Garcia, René (2000-01-01). „Incorporating second-order functional knowledge for better option pricing” (PDF). Proceedings of the 13th International Conference on Neural Information Processing Systems (NIPS'00). MIT Press: 451—457. „Since the sigmoid h has a positive first derivative, its primitive, which we call softplus, is convex.”
- ^ „Smooth Rectifier Linear Unit (SmoothReLU) Forward Layer”. Developer Guide for Intel Data Analytics Acceleration Library (na jeziku: engleski). 2017. Arhivirano iz originala 05. 12. 2021. g. Pristupljeno 2018-12-04.
- ^ Clevert, Djork-Arné; Unterthiner, Thomas. „Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)”. arXiv:1511.07289 [cs.LG].
- ^ Diganta Misra (23. 8. 2019), Mish: A Self Regularized Non-Monotonic Activation Function (PDF), arXiv:1908.08681v1 , Pristupljeno 26. 3. 2022Diganta Misra (23 Aug 2019), Mish: A Self Regularized Non-Monotonic Activation Function (PDF), arXiv:1908.08681v1, retrieved 26 March 2022
- ^ a b Shaw, Sweta (2020-05-10). „Activation Functions Compared with Experiments”. W&B (na jeziku: engleski). Pristupljeno 2022-07-11.